
Object detection is a computer technology linked to computer vision and image processing that is used for detecting instances of semantic objects of a certain class in digital images and videos.
You only look once (YOLO) is a state-of-the-art, real-time object detection system.
The idea of object detection method has been introduced to Indian sign language recognition. If we use traditional hand crafted features it will not work for every signs and addition of more symbols are become difficult. The YOLO is one of the best method in the object detection which is less computation than the other models.
The object detection models are R-CNN ,Faster R-CNN, SSD ,etc. These are the best methods for a faster and better recognition rate using the Deep Learning approach. The methods seems to be quite simple but there is some works needed for the development of object detection system.
In Sign Language recognition system , i have used threshold based method. But it will failed in various lightning conditions. This work is modeled with Tiny Yolo object detection model along 14 k image data-set( Collected from various people with different background at different position). All the images are labelled with labelimg graphical annotation tool. It is written in Python and uses Qt for its graphical interface.
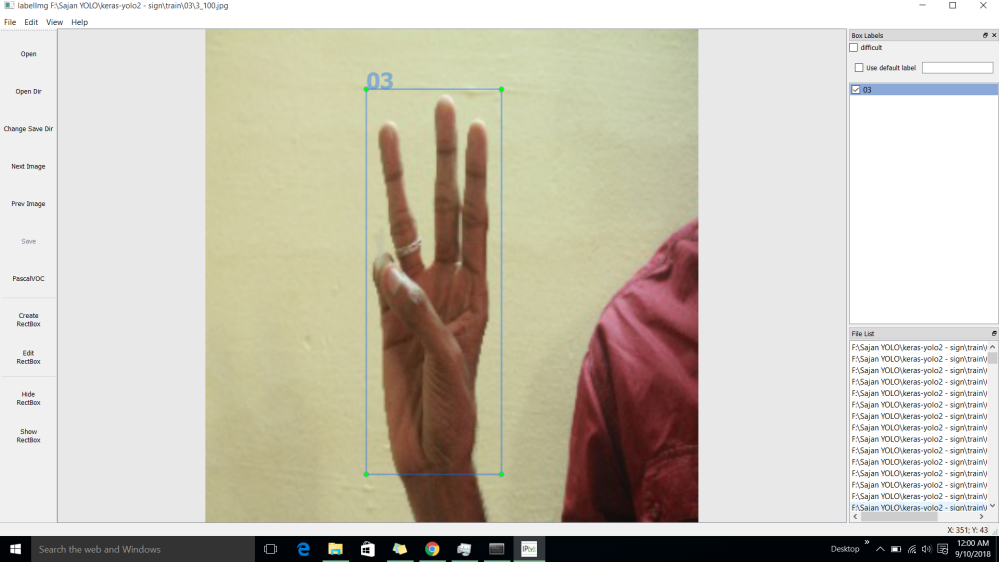
The annotation file will be saved as an XML file. The annotation format is PASCAL VOC format, and the format is the same as ImageNet

All the images are labelled with input size 288x288x3 and bounding box. The model is trained on intel Core i5 with NVIDIA GeForce 920MX GPU having CUDA support.
Data
While dealing with most of the deep learning system , the most import factor is the availability of data set. If the system has to produce the best result in real-time a large dataset has to be collected .The second thing is to create bounding box around the object. The data has to be labelled in each case with the object name and its co-ordinates . In my case i have created a data set 0f 14000 images of indian sign language and labelled them all in Pascal Voc format.
Computation
Most of the Deep Learning systems are computationally complex . The systems are trained in batches of size in order to fit in the memory. The system can be run on both cpu and gpu system but it is recommended to use gpu system. The cpu is slower and needs a large time for the training may takes days. In my case ,i have used keras model with tensorflow backend.(For python implementation both keras and keras-gpu versions are available)
The results of the trained model is given below.

One Comment Add yours